Einleitung
1.1.3 Prozedurale
und nichtprozedurale
Schnittstellen............................................................. 18
1.2 Relationale Datenbanken..................................................................................................... 25
1.3.2 Erste Normalform......................................................................................................... 37
1.5 Notation............................................................................................................................. 49
1 Einleitung
Das
Datenbanksystem INGRES ("INteractive Graphics and
REtrieval System") hat seinen
Ursprung in einem Projekt, das
von
Michael Stonebraker und Eugene
Wong an der Universität
von Kalifornien in
Berkeley in den
Jahren 1973-1975
durchgeführt wurde. Das
Ziel dieses Projektes
war, ein
relationales Datenbanksystem zu implementieren. Im Winter-
und
Sommersemester 1973/74 wurden
zwei Projektgruppen
gebildet, die die Erstellung einer Datenbanksprache und
die
Erzeugung einer Schnittstelle für die Datenzugriffe zur
Aufgabe hatten. Als Ergebnis
der Arbeit der ersten Gruppe
entstand die Datenbanksprache QUEL
("QUEry Language"),
während die zweite Projektgruppe fünf verschiedene
Zugriffsmethoden und den
Systemkatalog implementierte.
Für
beide Projekte wurde das Betriebssystem UNIX verwendet.
Im
Laufe der Zeit zeigte sich,
daß die Einbettung
der
Sprache QUEL in eine
Programmiersprache der dritten
Generation für die weitere
Entwicklung des Systems unbedingt
notwendig war. Als Ergebnis dieser Überlegungen entstand
EQUEL ("Embedded
QUEL") - ein
Vorübersetzer für die
Einbettung der QUEL-Anweisungen in
die Programmiersprache C.
Nachdem die anfänglichen Ziele
des Projektes erreicht
waren und ein Prototyp
erstellt war, wurde in der zweiten
Hälfte des Jahres 1975
damit begonnen, das ganze
System
leistungsfähiger und
zuverlässiger zu gestalten. Aus
diesem Grund wurde der
Schwerpunkt auf den konkurrierenden
Datenzugriff und die Datensicherheit
gelegt.
Im Jahre 1979 entschieden die beiden
Projektleiter, den
existierenden Prototyp
zu vermarkten. Deswegen
wurde
die Firma RTI (Relational Technology
Incorporated)
gegründet und die Codekonvertierung von UNIX
auf VMS, das
Standardbetriebssystem der DEC-Rechner, durchgeführt. Das
erste kommerzielle INGRES-Produkt enthielt zusätzlich einen
Listenprogrammgenerator sowie einen EQUEL-Vorübersetzer für
die
Sprachen BASIC, COBOL,
Fortran und Pascal. Dies waren
aus der Sicht der Benutzer gleichzeitig die wichtigsten
Einschränkungen des
INGRES-Prototyps.
In den Jahren 1981 - 1983
wurde zuerst das Dienstprogramm
QBF ("Query-by-Forms")
implementiert, das den Benutzern eine
einfache Schnittstelle zur Datenmanipulation bietet. In
dieser Zeit wurden auch ein anderer Optimierer (JOINOP) und
zwei weitere Benutzerschittstellen GBF
("Graph-by-Forms")
und RBF ("Report-by-Forms"), implementiert. GBF ermöglicht
den Benutzern, die Daten
in Grafikform auszugeben,
während RBF einen visuellen Editor für die Definition
von
Listenprogrammen darstellt.
Als
wichtige Neuigkeit in
diesem Zeitraum wurde
ABF
("Application-by-Forms") implementiert. ABF stellt
eine
Entwicklungsumgebung dar,
die für die
Datenmanipulation
das Dienstprogramm QBF und
für die Datenausgabe RBF
und
GBF verwendet. Damit
stellt ABF ein
interaktives,
formatorientiertes
Entwicklungssystem dar.
Ab
Mitte 1983 bis
Mitte 1984 wurde
der Schwerpunkt
der Firmenaktivitäten
auf ein besseres
Marketing- und
Verkaufsprogramm gelegt.
In diesem Zeitraum
wurden
auch einige technische Verbesserungen durchgeführt wie
die
Implementierung eines Subsystems
(INGRES/CS) für
Kleinrechner und die Darstellung von
Masken für Mehrtabellen
auf dem Bildschirm.
Im Bereich der verteilten
Datenverarbeitung hatte INGRES
von
Anfang an einen technologischen Vorsprung gegenüber
anderen relationalen Datenbanksystemen. Im Jahre 1983 wurde
mit
INGRES/NET das erste
Produkt freigegeben, das
einen
verteilten Zugriff auf Daten ermöglicht.
Damit war RTI die
erste Firma überhaupt, die ein
Produkt zur Unterstützung des
Server/Clients-Prinzips auf den
Markt gebracht hat.
Im Jahre 1986 wurde INGRES/STAR freigegeben, das als erstes
Produkt die Verteilung der Daten
im Netz unterstützte.
1987 wurde INGRES/PC eingeführt,
das eine Integration
von
Personal Computern in die
Datenverarbeitung eines
Unternehmens ermöglichte. Im Jahr darauf erweiterte RTI
die
INGRES-Produktpalette für die
verteilte Datenverarbeitung
um
Gateways, was einen verteilten Zugriff auf Datenbanken
unterschiedlicher Hersteller
ermöglichte.
1989 brachte RTI die
Multiserver-Architektur auf den
Markt. Damit war
INGRES das erste
Datenbanksystem, das
eine dynamische Zuweisung
zwischen den unterschiedlichen
Datenbank-Anwendungsprogrammen
("Front-Ends") einerseits und
verschiedenen Datenbank-Servern ("Back-Ends") andererseits
ermöglichte.
Anfang 1990 wurde das
INGRES-Datenbanksystem
erweitert.
Neben dem
Datenbank-Management, das das
bisherige
Datenbanksystem enthielt,
wurden
"Knowledge-Management"
und "Objekt-Management"
auf den Markt
gebracht.
"Knowledge-Management"
ermöglicht den Aufbau regelbasierter
Systeme, während "Objekt-Management" die objektorientierte
Schnittstelle zum Datenbanksystem
unterstützt.
Die
zuletzt freigegebene INGRES-Version,
Version 6.3, die im
vierten Quartal 1989 auf
den Markt gebracht wurde, bietet
eine neue Entwicklungsumgebung
INGRES/Windows-4GL. Dieses
Produkt ermöglicht die Erstellung von Datenbankanwendungen
mit
einer grafischen Benutzerschnittstelle. Die
mit
INGRES/Windows-4GL erstellten
Anwendungen können ohne
Programmodifikation unter
verschiedenen grafischen
Schnittstellen wie Open Look,
OSF/Motif usw. laufen.
Alle INGRES-Produkte
sind für eine
Vielzahl von
Betriebssystemen implementiert. Der wichtigste Bereich, in
dem
sie angeboten werden, ist der Rechnerbereich mit dem
Betriebssystem UNIX. Die UNIX-Version von INGRES existiert
für
die meisten UNIX-Derivate,
die entweder auf Intel-,
Motorola- oder anderen Prozessoren
laufen.
Im
Großrechnerbereich werden
INGRES-Produkte u.a. für DEC
VAX und Micro VAX (mit dem Betriebssystem VMS) angeboten.
In
der letzten Zeit erweist sich für
INGRES-Produkte der
Personal Computer-Bereich mit dem
Betriebssystem DOS als
immer wichtigerer Markt. Die
INGRES-Software unter DOS
enthält nur Datenbank-Anwendungen (front ends).
Trotzdem
sind die Unterschiede zwischen
INGRES-Produkten für
verschiedene Betriebssysteme minimal
und können deswegen
ignoriert werden. In diesem Buch
wird Bezug auf INGRES unter
dem Betriebssystem UNIX genommen.
Das
INGRES-Datenbanksystem
enthält, wie alle
anderen
relationalen Datenbanksysteme, zwei
Komponenten
- Datenbank-Anwendung
(front end) und
- Datenbank-Server (back end) .
Die Datenbank-Anwendungen
sind alle INGRES-Subsysteme
wie
INGRES/FORMS,
ESQL/C-Komponente usw. Aufgabe
des
Datenbank-Servers ist
es, alle in
einer Anwendung
programmierten Abfragen bzw. Änderungen auf die Daten einer
Datenbank durchzuführen.
Die Kommunikation
zwischen den Datenbank-Anwendungen
einerseits und dem
Datenbank-Server
andererseits hat bei
INGRES im Laufe der Zeit unterschiedliche Formen gehabt.
Bei
der ersten Form kommunizierte
jede Anwendung mit einem
Datenbank-Server, wie in Abbildung
1-1 dargestellt ist:
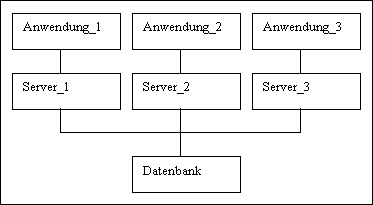
Abb. 1-1 1:1
Architektur
Der Nachteil dieser Kommunikationsform besteht
darin, daß
für
jede Datenbank-Anwendung
ein eigener Datenbank-Server
gestartet werden muß. Damit werden
für jeden Benutzer eines
Systems je 2 Prozesse
gestartet, was bei
einer großen
Benutzeranzahl Engpässe im
Arbeitsspeicher verursachen kann.
Eine
der nachfolgendenen INGRES-Versionen hatte eine andere
Kommunikationsform zwischen den
Datenbank-Anwendungen und dem
Datenbank-Server. In dieser Version wurde immer ein einziger
Datenbank-Server als Prozeß gestartet, der dann mit allen
Datenbank-Anwendungen, die in Bezug
zu einer INGRES-Datenbank
standen, kommunizierte.
Diese Kommunikationsform wird
oft
n:1-Architektur genannt. Sie
ist in Abbildung 1-2
dargestellt.
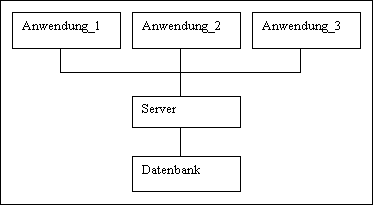
Abb. 1-2
n:1-Architektur
Der
Vorteil dieser Kommunikationsform liegt darin, daß
nur
n+1-Prozesse gestartet werden,
wobei n die Anzahl der
Benutzer einer INGRES-Datenbank darstellt. Bei einer großen
Anzahl der Benutzer, die auf
eine Datenbank zugreifen,
kann damit der befürchtete
Arbeitsspeicherengpaß vermieden
werden.
Diesem Vorteil steht folgender
Nachteil gegenüber: Die
Verwendung eines einzigen
Datenbank-Servers für eine große
Anzahl von
Datenbank-Anwendungen kann zum
Engpaß beim
Prozessor führen, an dem der
Datenbank-Server läuft.
INGRES Version 6 hat
eine dritte Kommunikationsform
zwischen den Datenbank-Anwendungen
und den Datenbank-Servern
hervorgebracht, die
beide Engpässe beseitigt. Diese
Kommunikationsform (auch Multi-Server-Architektur genannt)
ist gleichzeitig die fortschrittlichste von
allen
existierenden Kommunikationsformen.
Die Abbildung 1-3 stellt
die Multi-Server-Architektur dar.
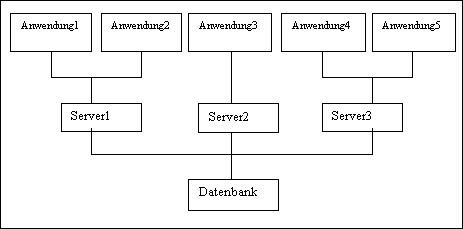
![]()
![]()
![]()
Abb.
1-3 m:n - Architektur
Bei
der
Multi-Server-Architektur
wird die Kommunikation
zwischen den
Datenbank-Anwendungen und
mehreren
Datenbank-Servern, von
welchen jeder einem
Prozessor
zugeordnet ist, frei gewählt.
(Deswegen wird diese
Kommunikationsform auch
m:n-Archtitekur genannt.) Die Anzahl
der
Prozesse bei der
m:n-Architektur liegt bei m+n, wobei
m
die Anzahl der Datenbank-Anwendungen
und n die Anzahl der
Datenbank-Server ist.
1.1 Datenbanken - allgemein
Bevor wir uns mit relationalen
Datenbanken befassen, soll der
Begriff der Datenbank allgemein
erläutert werden.
Eine Datenbank kann aus verschiedenen
Blickwinkeln betrachtet
werden, abhängig davon, in
welchem Zusammenhang sie gesehen
wird. Aus der Sicht eines Managers ist die Datenbank eine
Sammlung logisch zusammenhängender Daten, die ein Modell der
Aktivitäten seines Unternehmens
darstellen. Aus der Sicht
eines Datenbanksystems ist die Datenbank eine Sammlung von
physikalischen Daten.
Obwohl beide Betrachtungsweisen
diametral verschieden sind,
haben sie etwas gemeinsam:
Sie erfordern Funktionen, mit
denen eine
Datenbank abgefragt und modifiziert werden kann
sowie Schnittstellen, die maschinenunabhängig sind.
All
diese Funktionen und Schnittstellen soll ein Datenbanksystem
bieten. Zusammenfassend soll ein
Datenbanksystem folgendes
gewährleisten:
-
logische Datenunabhängigkeit;
-
physikalische Datenunabhängigkeit;
-
prozedurale und nichtprozedurale Schnittstellen;
-
effiziente Abarbeitung von Datenbankoperationen;
-
minimale Datenredundanz;
-
Datenintegrität;
-
konkurrierender Datenzugriff;
-
Datensicherheit und
-
Datenschutz.
Jede
dieser Grundeigenschaften eines Datenbanksystems soll
nachfolgend erläutert werden.
1.1.1 Logische Datenunabhängigkeit
Die logische
Datenunabhängigkeit
bezieht sich auf
unterschiedliche logische Sichten
einer Datenbank. Einerseits
existiert die logische Struktur
einer Datenbank mit allen
dazugehörigen Objekten
und Zusammenhängen, die
zwischen
diesen Objekten bestehen. Andererseits sieht jeder Benutzer,
der eine Datenbankanwendung programmiert
oder benutzt, nur
den
für ihn relevanten
Ausschnitt der gesamten
logischen
Struktur. Die logische
Unabhängigkeit bedeutet,
daß jeder
Benutzer seine Sicht der Datenbank erzeugen und
modifizieren
kann, ohne daß die logische
Gesamtstruktur geändert werden
müßte.
1.1.2 Physikalische Datenunabhängigkeit
Unter der physikalischen Datenunabhängigkeit versteht man die
Unabhängigkeit zwischen logischer und
physikalischer Struktur
einer Datenbank.
Die physikalische Datenunabhängigkeit garantiert,
daß die
physikalische Struktur
einer Datenbank beliebig
geändert
werden kann, ohne daß
dadurch die logische Struktur berührt
wird.
1.1.3 Prozedurale und nichtprozedurale Schnittstellen
Bei
Datenbanksystemen
existieren u.a. zwei
Arten von
Benutzern, nämlich der Programmierer und der Endbenutzer.
Die
Aufgabe eines Programmierers ist es, Programme
zu
schreiben, mit denen eine
Datenbank abgefragt oder
modifiziert werden kann. Endbenutzer sind in der Regel keine
DV-Fachleute. Sie greifen auf die Datenbank über eine
leicht
erlernbare Kommandosprache zu. Falls
auf der Ebene dieser
Kommandosprache Kontrollstrukturen
angeboten werden, wie z.B.
THEN wahr_zweig
ELSE falsch_zweig
spricht man von einer
prozeduralen, ansonsten von einer
nichtprozeduralen Schnittstelle.
Ein
Programmierer hat in
den meisten Fällen
weitaus
komplexere Aufgabenstellungen
zu erledigen als
ein
Endbenutzer und benötigt
daher nahezu immer
Programmiersprachen mit
einem umfangreichen Spektrum
an
Kontrollstrukturen. Dementsprechend sind alle bekannteren
Datenbankschnittstellen für
Programmierer prozedurale
Schnittstellen.
1.1.4 Effiziente Abarbeitung der Datenbankoperationen
Mit
der Verwendung mächtiger
Datenbankprogrammiersprachen
wird die Entwicklungszeit von
Datenbankanwendungen in
der
Regel reduziert, oft
allerdings auf Kosten
von
zusätzlichen E/A-Operationen und längerer
Verarbeitungszeit.
Das
Datenbanksystem sollte daher
für die Abarbeitung
der
jeweiligen Datenbankoperation
eine optimale Strategie
entwickeln können.
1.1.5 Minimale Datenredundanz
In
dateiorientierten Anwendungen, bei
denen jeder
Benutzer seine Dateien unabhängig von den anderen
Benutzern verarbeitet,
existiert zwangsläufig eine
große
Menge redundanter Daten. Durch
diese wird unnötig
viel
Speicherplatz verbraucht. Daneben werfen redundante Daten
im
Falle einer Änderung erhebliche Probleme auf, weil es in der
Regel nicht möglich ist, redundante
Daten synchronisiert zu
modifizieren. Eine wesentliche
Aufgabe jedes Datenbanksystems
ist es daher, die
Datenredundanz zu minimieren. Die
später
in diesem Kapitel beschriebenen Normalformen ermöglichen die
Minimierung der Datenredundanz.
1.1.6 Datenintegrität
Ein
Datenbanksystem sollte
offensichtlich unsinnige Daten
erkennen und abweisen können.
(Das Datum 30. Februar oder
die Uhrzeit 17:77:00 sind typische
Beispiele.) Daneben ist
es wünschenswert, gegenüber dem Datenbanksystem Begrenzungen
oder Formatangaben zu Eingabedaten deklarieren zu können,
z.B.:
Jahrgang > 1949
Ausgereifte Datenbanksysteme stellen
außerordentlich komplexe
Mechanismen zur Plausibilitätsprüfung von Eingabedaten zur
Verfügung. Dazu gehört insbesondere
die Fähigkeit, bereits in
der Datenbank vorhandene Daten in die Plausibilitätsprüfung
mit einzubeziehen.
1.1.7 Konkurrierender Datenzugriff
Der Umstand, daß im Regelfall viele
Benutzer gleichzeitig auf
eine Datenbank zugreifen, wirft eine
Reihe von Problemen auf.
Ein
besonders gravierendes Problem wird durch das folgende
Beispiel erläutert:
1) Auf dem Konto 4711 der Bank X
befinden sich 10.000DM.
2) Die Kunden A und B gehen in zwei
verschiedene Filialen der
Bank X und heben gleichzeitig 10.000DM vom Konto 4711 ab.
3) Die Kassierer in beiden
Bankfilialen bekommen vom
Datenbanksystem den Kontostand
10.000DM gezeigt.
4) Beide Kassierer zahlen jeweils
10.000DM aus und ändern das
Konto 4711 mit dem Wert 10.000 DM
minus 10.000 DM gleich
0 DM.
5) Es ist nun unerheblich, in welcher
Reihenfolge diese
beiden Änderungen ausgeführt
werden; das Konto 4711 steht
auf 0 DM statt auf -10.000 DM.
Der ganze Problemkreis des konkurrierenden Datenzugriffs,
der hier aufgezeigt wurde,
muß von einem
Datenbanksystem
natürlich mit völliger Korrektheit abgehandelt werden.
Bezogen auf das
vorangehende Beispiel bedeutet dies, daß ein
Datenbanksystem den Kontostand von -10.000 DM garantieren
muß, nachdem beiden Kunden je 10.000
DM ausgezahlt wurden.
1.1.8 Datensicherheit
Der
Begriff der Datensicherheit bezieht sich auf den Ausfall
von Hardware und/oder Software. Ein Datenbanksystem
sollte
in
der Lage sein, nach denkbaren Ausfällen die betroffenen
Datenbanken automatisch in den letzten konsistenten Stand zu
überführen.
1.1.9 Datenschutz
Eine
Datenbank sollte gegen unerlaubten Zugriff
geschützt
werden können. Entsprechende Möglichkeiten, wie Vergabe und
Entzug der Zugriffsrechte, sollte
jedes Datenbanksystem
unterstützen.
1.2 Relationale Datenbanken
Der Begriff der relationalen Datenbanken
wurde 1970 von
E.F.Codd eingeführt. In dem Artikel "A Relational Model of
Data for Large Shared Data
Banks" wurde die theoretische
Grundlage für
relationale Datenbanken festgelegt: Das
sogenannte relationale Datenmodell.
Im Unterschied zu anderen
Datenbanksystemen (netzwerkartigen bzw. hierarchischen
Systemen), basiert das relationale
Modell völlig auf den
mathematischen Grundlagen der
relationalen Algebra.
Eine
Erklärung der relationalen
Algebra liegt außerhalb der
Ziele dieses Buches. Wir werden die
wichtigsten Eigenschaften
des relationalen
Modells mit Hilfe einer Beispieldatenbank
erklären. Weiter dient
die Beispieldatenbank als
Grundlage
für alle praktischen Beispiele
innerhalb dieses Buches.
Das
Grundelement einer relationalen Datenbank ist die
Tabelle. Aus der Benutzersicht besteht jede relationale
Datenbank nur aus Tabellen.
Eine Tabelle setzt sich aus
Reihen und Spalten zusammen, d.h.
sie beinhaltet keine,
eine oder mehrere Reihen und eine
oder mehrere Spalten. Das
Objekt, das genau zu einer Reihe und einer
Spalte gehört,
heißt Datenwert oder Datum.
Die
Beispieldatenbank enthält die
Datenwerte einer Firma,
die in mehrere Abteilungen unterteilt ist. Jeder Mitarbeiter
der Firma gehört zu einer der existierenden Abteilungen an.
Die
Eigenschaft unserer Firma
ist, daß die
Mitarbeiter
ihre
Tätigkeiten in verschiedenen
Projekten ausüben. Jeder
Mitarbeiter kann
in verschiedenen Projekten
arbeiten und
dabei unterschiedliche Aufgaben
wahrnehmen.
Die Datenbank besteht bei uns aus
vier Tabellen:
abteilung
mitarbeiter
arbeiten .
Die
Tabelle abteilung stellt alle
Abteilungen der Firma dar.
Jede Abteilung ist auf folgende Weise
beschrieben:
abteilung (abt_nr, abt_name, stadt)
abt_nr
ist die für jede Abteilung
der Firma eindeutige
Abteilungsnummer. abt_name steht für den Namen der
Abteilung;
stadt
für die Stadt, in der sich diese Abteilung befindet.
Die
Tabelle mitarbeiter beinhaltet alle
Mitarbeiter der
Firma. Jeder Mitarbeiter ist auf
folgende Weise beschrieben:
mitarbeiter (m_nr, m_name, m_vorname, abt_nr)
m_nr kennzeichnet die für jeden
Mitarbeiter eindeutige
Personalnummer. m_name
und m_vorname kennzeichnen Namen und
Vornamen des Mitarbeiters, während abt_nr die
Nummer der
Abteilung benennt, welcher der
Mitarbeiter angehört.
Die Tabelle projekt stellt alle Projekte der Firma dar. Jedes
Projekt ist dabei auf folgende Weise
beschrieben:
projekt (pr_nr, pr_name, mittel)
pr_nr
bezeichnet die innerhalb der Firma
eindeutige Nummer
des Projektes. pr_name
und mittel kennzeichnen den
Namen
des Projektes bzw. die
Geldmittel, die für das Projekt
zur
Verfügung stehen. Die Geldmittel sind
in DM angegeben.
Die
Tabelle arbeiten beschreibt die
Beziehung zwischen
den
Mitarbeitern und den
Projekten. Diese Tabelle ist auf
folgende Weise beschrieben:
arbeiten (m_nr, pr_nr, aufgabe, einst_dat)
m_nr zeigt die Personalnummer des Mitarbeiters
und pr_nr die
Nummer des Projektes, in dem der Mitarbeiter
arbeitet, an.
Die Kombination aus m_nr und pr_nr ist innerhalb
der Firma
eindeutig. aufgabe beschreibt die Funktion
des Mitarbeiters
(mit
der Personalnummer m_nr)
innerhalb des Projektes (mit
der
Nummer pr_nr). einst_dat kennzeichnet das
Eintrittsdatum
des Mitarbeiters in das Projekt.
Die
relationale Datenbank für
das soeben beschriebene
Schema ist in Abbildung 1-4a bis
1-4d dargestellt. (Die
Primärschlüssel aller Tabellen sind im Unterschied zu den
anderen Spalten invers dargestellt.)
|
abt_nr |
abt_name |
stadt |
|
a1 |
Beratung
|
Muenchen |
|
a2
|
Diagnose |
Muenchen |
|
a3 |
Freigabe
|
Stuttgart |
Abb. 1-4 a)
Tabelle abteilung
|
m_nr |
m_name |
m_vorname |
abt_nr |
|
25348 |
Keller
|
Hans |
a3 |
|
10102 |
Huber |
Petra |
a3 |
|
18316 |
Mueller |
Gabriele |
a1 |
|
29346 |
Probst |
Andreas |
a2 |
|
9031 |
Meier |
Rainer |
a2
|
|
2581 |
Kaufmann
|
Brigitte |
a2 |
|
28559 |
Mozer |
Sibille |
a1
|
Abb. 1-4 b)
Tabelle mitarbeiter
|
pr_nr |
pr_name |
Mittel |
|
p1 |
Apollo |
120000 |
|
p2 |
Gemini |
95000 |
|
p3 |
Merkur
|
186500
|
Abb. 1-4 c)
Tabelle projekt
|
m_nr |
pr_nr |
aufgabe |
einst_dat |
|
10102 |
p1 |
Projektleiter |
01-oct-1988 |
|
10102 |
p3 |
Gruppenleiter |
01-jan-1989 |
|
25348 |
p2 |
Sachbearbeiter |
15-feb-1988 |
|
18316 |
p2 |
|
01-jun-1989 |
|
29346 |
p2 |
|
15-dec-1987 |
|
2581 |
p3 |
Projektleiter |
15-oct-1989 |
|
9031 |
p1 |
Gruppenleiter |
15-mar-1989 |
|
28559 |
p1 |
|
01-aug-1988 |
|
28559 |
p2 |
Sachbearbeiter |
01-feb-1989 |
|
9031 |
p3 |
Sachbearbeiter |
15-nov-1988 |
|
29346 |
p1 |
Sachbearbeiter |
01-apr-1989 |
Abb. 1-4 d)
Tabelle arbeiten
Mit
Hilfe unseres Beispiels können wir jetzt einige wichtige
Eigenschaften des relationalen
Modells erklären:
- die Reihen innerhalb einer
Tabelle können beliebige
Reihenfolge haben;
- die Spalten innerhalb einer
Tabelle können beliebige
Reihefolge haben;
- alle Datenwerte einer Spalte
haben genau denselben
Datentyp;
- jede Spalte hat einen eindeutigen Namen innerhalb einer
Tabelle. Spalten, die verschiedenen
Tabellen angehören,
können durchaus denselben Namen haben. (Beispiel: Die
Spalte m_nr in der Tabelle arbeiten
und die Spalte m_nr in
der Tabelle mitarbeiter.);
- jeder einzelne Datenwert innerhalb
einer Tabelle ist durch
einen einzigen Wert dargestellt.
Das heißt: In einer Reihe
und innerhalb einer Spalte
können sich nie mehrere Werte
gleichzeitig befinden.
- in jeder Tabelle einer relationalen Datenbank existiert
ein (oder mehrere) Bezeichner, der jede Reihe der
Tabelle
eindeutig definiert. Dieser
Bezeichner kann entweder aus
einer Spalte oder aus
einer Kombination mehrerer Spalten
bestehen. Im relationalen Modell
heißt dieser Bezeichner
Primärschlüssel. Die Spalte abt_nr ist der Primärschlüssel
in der Tabelle abteilung;
m_nr ist der Primärschlüssel in
der Tabelle mitarbeiter; pr_nr ist der Primärschlüssel in
der Tabelle projekt und die Kombination der Spalten (m_nr,
pr_nr) ist der
Primärschlüssel in der Tabelle arbeiten.
- in einer Tabelle existieren nie
zwei identische Reihen;
(Diese Eigenschaft wird von INGRES und allen anderen
relationalen Datenbanksystemen
nicht unterstützt.)
Hinweis
In
der Terminologie
relationaler Datenbanken existieren
mehrere analoge Begriffe. So
entsprechen die mathematischen
Begriffe Relation, Tupel und
Attribut in der
Praxis
existieren in der Praxis
weitere Begriffe wie
Satz oder
Record (für Reihe), Feld
(für Spalte) usw.
In diesem
Buch werden nur die Begriffe
benutzt, die im SQL-Standard
verwendet wurden, also Tabelle, Reihe
und Spalte.
1.3 Datenbankdesign
Das
Datenbankdesign ist eine
sehr wichtige Phase,
die
der
Erstellung einer Datenbank
vorangeht. Falls das
Datenbankdesign intuitiv und ohne sorgfältige
Analysephase
entworfen wird, ist die daraus
resultierende Datenbank in den
meisten Fällen nicht optimal an die Aufgabe, zu deren
Lösung
sie
aufgebaut wurde, angepaßt.
Die daraus resultierende
Folge kann überflüssige
Datenredundanz, mit damit verbundenen
Nachteilen für Speicherverbrauch und
Datenkonsistenz sein.
Die
Normalisierung der Daten
stellt ein Verfahren dar, in
dem die Datenredundanz stufenweise
reduziert werden kann. Mit
der Normalisierung der Daten
wird ein weiteres Ziel - die
logische Unabhängigkeit der Daten -
verfolgt.
Insgesamt existieren fünf Normalformen,
von welchen wir die
ersten vier erläutern werden. Die
fünfte Normalform hat keine
bzw. sehr geringe praktische
Bedeutung. Jede Normalform ist
in der nachfolgenden enthalten.
1.3.1 Allgemeine Hinweise zur Normalisierung
Der Prozeß der Normalisierung einer
Datenbank sollte immer
mit der ersten Normalform beginnen.
Nachdem die Datenbank die
erste Normalform erfüllt, sollten die Tabellen der Datenbank
so
zerlegt werden, daß sie die zweite
Normalform erfüllen
usw. Für die meisten Datenbanken
genügt die Normalisierung
bis einschließlich der dritten
Normalform. Die vierte und
insbesondere die fünfte
Normalform finden in
der Praxis
selten Anwendung.
Die im Zusammenhang mit der
Normalisierung entscheidende
Frage ist, wieviel
Datenredundanz sinnvoll ist. Diese Frage
kann nur für jede Datenbank
separat beantwortet werden. Das
wichtigste Kriterium für
diese Entscheidung ist,
ob die
Datenbank wenigen oder vielen
Änderungen unterworfen ist. Die
Datenbanken, die wenigen oder keinen Änderungen unterworfen
sind, können problemlos mehr
Datenredundanz enthalten.
Demgegenüber sollten die
Datenbanken, die häufig geändert
werden, möglichst wenig redundante Daten haben, weil
das
Ziel, die redundanten Daten
konsistent zu halten, i.a. nur
mit hohem Aufwand zu erreichen ist.
1.3.2 Erste Normalform
Eine
Tabelle ist in der ersten Normalform, falls in jeder
Reihe und für jede Spalte nur
atomare Werte existieren.
Wie aus dem vorherigen Abschnitt
ersichtlich, beinhaltet
das
relationale Modell an sich schon
diese Eigenschaft. Die
erste Normalform werden wir anhand eines Ausschnitts aus der
Tabelle arbeiten der Beispieldatenbank darstellen:
|
10102 |
p1 |
..... |
|
10102 |
p3 |
..... |
|
..... |
.... |
...... |
Falls diese zwei Reihen
folgendermaßen geschrieben würden:
|
10102 |
(p1,
p3) |
..... |
|
..... |
........ |
...... |
würde die Tabelle arbeiten
nicht in der ersten Normalform
sein. (Dies ist im relationalen
Modell nicht möglich.)
1.3.3 Zweite Normalform
Eine
Tabelle befindet sich
in der zweiten Normalform,
wenn jede Spalte dieser
Tabelle, die den
Primärschlüssel
nicht bildet, voll funktional abhängig von jedem
Teil des
Primärschlüssels ist. Nehmen wir an,
die Tabelle arbeiten der
Beispieldatenbank enthält folgende
Spalten:
|
m_nr |
pr_nr |
aufgabe |
einst_dat |
abt_nr |
|
10102 |
p1 |
Projektleiter |
01-oct-1988 |
a3 |
|
10102 |
p3 |
Gruppenleiter |
01-jan-1989 |
a3 |
|
25348 |
p2 |
Sachbearbeiter |
15-feb-1988 |
a3 |
|
18316 |
p2 |
|
01-jun-1989 |
a1 |
|
|
|
|
|
|
Den Primärschlüssel dieser Tabelle
bildet die Kombination der
Spalten m_nr und pr_nr.
Die Spalte abt_nr ist nicht voll
funktional vom kompletten Primärschlüssel, sondern schon von
einem Teil(m_nr) abhängig.
Deswegen befindet sich die oben
abgebildete Tabelle nicht in
der zweiten Normalform. (Die
Tabelle arbeiten der
Beispieldatenbank befindet sich in der
zweiten Normalform.)
1.3.4 Dritte Normalform
Die
dritte Normalform besagt,
daß zwischen den
Spalten
einer Tabelle, die nicht
den Primärschlüssel bilden, keine
Abhängigkeiten existieren
dürfen. Ausgegangen wird
dabei
immer von einer Tabelle,
die sich bereits in der
zweiten
Normalform befindet. Nehmen wir an,
die Tabelle mitarbeiter
enthält eine zusätzliche Spalte mit dem Namen der Abteilung:
|
m_nr |
m_name |
m_vorname |
abt_nr |
abt_name |
|
25348 |
Keller |
Hans |
a3 |
Freigabe |
|
10102 |
Huber |
Petra |
a3 |
Freigabe |
|
18316 |
Mueller |
Gabriele |
a1 |
Beratung |
|
29346 |
Probst |
Andreas |
a2 |
Diagnose |
|
|
|
|
|
|
Der Primärschlüssel dieser Tabelle ist die
Spalte m_nr. Weil
die Spalten abt_nr und abt_name
voneinander abhängig sind
und keine von beiden Teil des Primärschlüssels ist, befindet
sich
die oben abgebildete Tabelle
nicht in der
dritten
Normalform. (Die Tabelle mitarbeiter, genauso
wie alle
anderen Tabellen der Beispieldatenbank, befindet sich in der
dritten Normalform.)
Datenbanken, die die dritte
Normalform erfüllen, enthalten
weitgehend nicht redundante Daten.
1.3.5 Vierte Normalform
Die
vierte Normalform beseitigt die mehrwertigen
Abhängigkeiten in
den Tabellen einer
Datenbank. Als
praktisches Beispiel betrachten wir die Tabelle verkauf, mit
welcher der Verkauf diverser
Artikel in verschiedenen Läden
abgewickelt wird.
|
art_nr |
laden_nr |
farbe |
|
art_1 |
laden_1 |
schwarz |
|
art_1 |
laden_1 |
weiß |
|
art_2 |
laden_1 |
rot |
|
art_2 |
laden_1 |
schwarz |
|
art_2 |
laden_2 |
rot |
|
art_2 |
laden_2 |
schwarz |
|
art_3 |
laden_2 |
weiß |
|
|
|
|
Die Tabelle verkauf erfüllt die
dritte Normalform, weil der
einzige Primärschlüssel die
Kombination aller drei Spalten
art_nr,
laden_nr und farbe ist.
Trotzdem sind die Datenwerte
dieser Tabelle redundant. Der
Grund für die Redundanz liegt
darin, daß jeder Artikel sowohl
in mehreren Läden verkauft
wird als auch mehrere möglichen Farben hat. Der
Artikel
art_2
z.B. wird in zwei Läden verkauft: laden_1
und laden_2
und in zwei verschiedenen Farben
schwarz und rot. Deswegen
existieren in der Tabelle verkauf mehrwertige Abhängigkeiten,
die mit der Trennung in
zwei Tabellen beseitigt
werden
können.
1.4 INGRES-Datenbanksprachen
INGRES unterstützt zwei Datenbanksprachen - QUEL und
SQL. QUEL ist die Sprache, die
von der INGRES-Manschaft
implementiert wurde
und ursprünglich als
Teil dieses
Datenbanksystems gedacht war. Die
Sprache SQL wurde
erst
später portiert, nachdem sich abgezeichnet hatte, daß diese
Sprache die Standardsprache für relationale Datenbanksysteme
wird.
Obwohl viele Datenbankexperten
glauben, daß QUEL technisch
gesehen eine bessere Datenbanksprache als SQL ist, verliert
QUEL
immer mehr an
Bedeutung. Deswegen werden
wir in
diesem Buch ausschließlich die
INGRES-Schnittstelle zu SQL
beschreiben und verwenden.
In
folgendem Abschnitt wird die
Entwicklung der SQL-Sprache
erläutert.
1.4.1 Die Datenbanksprache SQL
SQL
ist eine Datenbanksprache, die
auf dem relationalen
Datenmodell
basiert. Der Name
steht als Abkürzung
für "Structured Query
Language", d.h. strukturierte
Abfragesprache.
Die Entstehungsgeschichte von SQL
ist eng mit dem Projekt
"System R" bei
IBM verbunden. "System
R" sollte beweisen,
daß
ein relationales Datenbanksystem allen praktischen
Anforderungen gerecht werden kann.
Ein derartiges System soll
also sehr leistungsfähig sein und
alle Funktionen beinhalten,
die für die alltägliche
praktische Anwendung notwendig sind
[CHA81].
Die
Entwicklung von "System R" war in
drei Phasen
untergliedert. Das Ziel
der ersten Phase
("Phase Null")
war
die schnelle Implementierung
eines Prototyps, der nur
einen Teil der vorgesehenen
Funktionen beinhalten sollte.
Als Datenbanksprache wurde in dieser Phase "SEQUEL"
gewählt.
Für diese Sprache wurde ein Interpreter in PL/I geschrieben,
der
ihre Anweisungen ausführen
konnte. Im weiteren Verlauf
dieser Phase wurde der Name der Sprache in "SQL" geändert.
Trotz dieser Änderung wird SQL heute
noch häufig als "Sequel"
(sprich: "siekwel") ausgesprochen.
Die implementierte
Untermenge der SQL-Sprache bot
die Möglichkeit,
sowohl die Datenbank abzufragen
und
zu modifizieren als
auch dynamische Änderungen
des
Datenbankdesigns
durchzuführen. Zusätzlich wurden
Unterabfragen implementiert. Damit war es möglich, die
Suche
in
mehreren Tabellen durchzuführen;
das endgültige Ergebnis
konnte nur aus einer Tabelle
entnommen werden.
In
dieser Phase wurde
"System R" als
Einplatzsystem
implementiert,
d.h. die Abfragen mittels SQL konnten nur von
einem Bildschirm aus gestartet werden. Die schwerste Aufgabe
in
dieser Phase war die Arbeit an optimierenden Algorithmen.
Das Ziel war, die Anzahl der Zugriffe auf Datenbanken bei
Abfragen zu minimieren.
Diese Phase dauerte zwei Jahre,
von 1974 bis 1975, und hat
in
bezug auf SQL bewiesen, daß die
Sprache in der Praxis
einsetzbar war.
Die zweite Phase von "System
R", "Phase Eins",
dauerte von
1976 bis Mitte 1977. Der Prototyp aus der ersten Phase wurde
jedoch nicht weiterentwickelt,
sondern eine ganz neue Version
von
"System R"
konstruiert. Diese Version
beinhaltete alle
schon erwähnten Funktionen und
war ein Mehrplatzsystem. Die
wichtigsten Komponenten der zweiten
Phase, in bezug auf SQL
waren die Implementierung von Abfragen, die mehrere Tabellen
verknüpfen, und das Subsystem
für Datenschutz. Dieses
Subsystem sicherte jedem Benutzer
genau den Zugriff zu, der
ihm vom Eigentümer des
entsprechenden Objektes eingeräumt
wurde.
Zusätzlich dazu wurde SQL in zwei
höhere Programmiersprachen,
COBOL und PL/I, eingebettet. Das Ziel war,
jedem
Programmierer dieselben Möglichkeiten zu geben,
ungeachtet
dessen, ob er interaktive
Abfragen oder die COBOL- bzw.
PL/I-Schnittstelle benutzt. Das erklärte Ziel der zweiten
Phase war, "System R" für die IBM-Betriebssysteme VM/CMS und
MVS/TSO lauffähig zu machen.
In der dritten Phase, von
Juni 1977 bis Ende 1979, wurde
"System R" intern bei IBM und bei drei
ausgewählten Kunden
getestet. Die SQL-Benutzerschnittstelle von "System R" wurde
generell als einfach und
mächtig bewertet. Die Sprache
war
so
strukturiert, daß die Anwender sie in relativ kurzer Zeit
erlernen konnten.
Nach dem Erfolg von "System
R" war klar, daß IBM marktreife
Produkte auf der Basis von
"System R" entwickeln würde, die
auch
SQL beinhalten sollten. Trotzdem war es
ein anderes
Produkt - ORACLE von Relational
Software Inc. -, das
als
erstes relationales Datenbanksystem im Jahre 1980 auf den
Markt kam. 1981 kam das erste
relationale Datenbanksystem von
IBM - SQL/DS heraus. Die erste
Version von SQL/DS war für das
Betriebssystem DOS/VSE freigegeben, die nächste (1982) für
VM/CSM. Im Jahre 1983 gab IBM
ein weiteres relationales
System - DB2 - frei. DB2 war
weitgehend kompatibel zu SQL/DS.
In
den folgenden Jahren
gaben weitere Hersteller
ihre
relationalen Datenbanksysteme frei,
wie SQL-Schnittstelle für
INGRES (Relational Technology Inc.,
1985) usw.
Im
Jahre 1982 gründete
das American National
Standards
Institute (ANSI) ein Gremium,
das einen Standard
für
relationale Datenbanksprachen
entwerfen sollte. Im
Laufe
der Zeit wurde zum größten
Teil der SQL-Dialekt von IBM
als Standard übernommen und im Oktober 1986 verabschiedet
[ANS86].
Nach der Verabschiedung des ersten
SQL-Standards hat sich
dasselbe Gremium dem Entwurf
eines neuen Standards
mit
dem Namen SQL2 gewidmet. Bis heute sind einige
vorläufige
Entwürfe des SQL2-Standards veröffentlicht worden, von
welchen der letzte im April 1991
erschienen ist. [ANS91]
1.5 Notation
Für
die Darstellung der
Syntax aller in
diesem Buch
definierten SQL-Anweisungen
wird eine einfache
formale
Sprache benutzt, die nachfolgend
definiert wird:
|
Notation |
Bedeutung |
|
SCHLÜSSELWORT |
Jedes Schlüsselwort der SQL-Sprache wird in
Großbuchstaben angegeben. (Beispiel: CREATE
TABLE). Zusätzliche Erklärungen zu Schlüsselwörtern können Sie in
Kapitel 2 finden. |
|
variable |
Die Schreibweise mit Kleinbuchstaben
bezeichnet eine Variable. Beispiel: CREATE TABLE tabelle (für „tabelle“ muß
ein aktueller Wert eingegeben werden). |
|
var_1|var_2 |
Alternative Darstellung: Einer der
Ausdrücke, der durch einen senkrechten Strich von den anderen getrennt ist,
ist auszuwählen, z.B. ALL|DISTINCT. |
|
[ ] |
Eckige Klammern bezeichnen optionale Werte.
Werte innerhalb der eckigen Klammern dürfen also weggelassen werden. |
|
Voreinstellung |
Unterstrichene Werte kennzeichnen die
Voreinstellung. Dieser Wert wird also implizit angenommen, wenn
explizit keine Alternative angegeben ist. |
|
Wiederholungszeichen: Der unmittelbar vorhergehende Ausdruck
darf mehrmals wiederholt werden (getrennt durch ein oder mehrere
Leerzeichen). |
|
|
Der Ausdruck, der innerhalb der
geschweiften Klammern erscheint, darf mehrmals wiederholt werden (getrennt durch ein oder mehrere
Leerzeichen). |
Zusätzlich zur Notation werden
alle Objekte der
Beispieldatenbank im Text
fettgedruckt dargestellt.
Die
Schlüsselwörter in Maskten bzw.
Listenprogrammen werden
fettgedruckt und mit Kleinbuchstaben
geschrieben.
Aufgaben
Datenunabhängigkeit existieren?
A.1.2
Welches ist das
Grundelement einer relationalen
Datenbank?
A.1.3
Was stellt die Tabelle arbeiten in Bezug auf die anderen
Tabellen dar?