Speicherstrukturen und Indexe
12 Speicherstrukturen und Indexe
12.2.1 SQL-Anweisungen in Bezug auf Indexe
12.2.3 Kriterien zur Erstellung eines Index
12.3 Allgemeine Kriterien zur Verbesserung
der Effizienz
12.3.1 Join statt korrelierter Unterabfrage
12.3.2 Unvollständige Anweisungen
12.4 Optimieren von Suchanweisungen
12 Speicherstrukturen und Indexe
In
diesem Kapitel werden
zunächst die von
INGRES
unterstützten
Speicherstrukturen dargestellt und ihre
Rolle
beim Zugriff auf Daten
erläutert. Im weiteren Verlauf
des
Kapitels werden Indexe definiert
und alle SQL-Anweisungen,
die Indexe betreffen, erklärt. Am
Ende des Kapitels werden
die
Möglichkeiten dargestellt, die
INGRES bietet, um die
Optimierung der Suchanweisungen zu
beeinflussen.
12.1 Speicherstrukturen
Die
Reihen aus einer
Tabelle werden mit
Hilfe der
SELECT-Anweisung ausgewählt. Die WHERE-Klausel innerhalb
einer
SELECT-Anweisung schränkt die
Menge der ausgewählten
Reihen und damit auch der
Datenwerte ein. Die Suche
nach
Datenwerten, die
durch eine SELECT-Anweisung mit der
WHERE-Bedingung festgelegt sind, kann auf zwei verschiedene
Weisen durchgeführt werden:
- sequentiell und
- direkt.
Sequentielle Suche bedeutet, daß jede Reihe
der Tabelle
einzeln auf die Bedingung in der
WHERE-Klausel überprüft
wird. Nacheinander werden also
alle Reihen in
der
Reihenfolge, wie sie physikalisch
gespeichert sind, geprüft.
Die direkte Suche kennzeichnet das
gezielte Suchen nach den
Reihen, die die angegebene Bedingung
erfüllen. Welche Art der
Suche angewendet wird, hängt primär
von der Speicherstruktur,
mit der die Reihen einer Tabelle
auf der Platte gespeichert
sind, ab. Einige Speicherstrukturen erlauben den Zugriff auf
Daten mit Hilfe eines Schlüssels.
In diesem Fall ist
die
direkte Suche möglich. Falls der Zugriff auf
Daten ohne
Schlüssel durchgeführt wird, muß
die sequentielle Suche
angewendet werden.
INGRES unterstützt insgesamt vier unterschiedliche Arten von
Speicherstrukturen:
- Stapel
("heap"),
- Hash,
- ISAM
und
- BTREE.
12.1.1
Stapel
Der Stapel kennzeichnet die Speicherstruktur, bei der
die
Reihen ungeordnet sind, d.h. beim
Stapel wird jede neue Reihe
am Dateiende angefügt.
Alle Tabellen bei INGRES
werden bei ihrer
Erstellung
standardmäßig in Form eines Stapels gespeichert. Die
einzige
Ausnahme bildet die Tabelle,
die mit Hilfe der AS-Angabe
aus einer existierenden Tabelle abgeleitet ist. (Für weitere
Einzelheiten siehe die Beschreibung
der SET Anweisung mit der
RESULT_STRUCTURE-Angabe später in
diesem Kapitel.)
Der Stapel kann sehr effektiv zum
Einfügen der Reihen einer
Tabelle angewendet werden. Andererseits muß jede
Suche in
einem Stapel sequentiell durchgeführt werden, was eine
Ineffizienz dieser Operation nach
sich zieht.
12.1.2 Hash
Die
Hash-Speicherstruktur
basiert auf einer
Funktion
(Hash-Funktion), die auf
eine oder mehrere Spalten
einer
Tabelle (Hash-Schlüssel) angewendet wird. Im Unterschied zum
Stapel basiert das Hash-Verfahren auf einem Schlüssel, d.h.
die Reihen der Tabelle sind auf Grund des
Hash-Schlüssels
geordnet.
Mit
der Hash-Funktion wird die
Adresse eines physikalischen
Blockes direkt aus dem vorgegebenen Schlüsselwert berechnet.
Damit kann der Block,
in dem sich die gesuchte
Reihe
befindet, meistens mit einer einzigen
E/A-Operation ermittelt
werden.
Das
Hash-Verfahren kann
effektiv bei der
Suche mit dem
kompletten Schlüsselwert
angewendet werden. Falls
der
Schlüsselwert nur
teilweise bekannt ist
(z.B. m_name
LIKE
'K%'), wird dieses
Verfahren ineffektiv, weil
die
Hash-Funktion den kompletten Wert des Schlüssels braucht,
um ihn im Speicher ausfindig
zu machen. Genauso ist das
Hash-Verfahren ineffektiv
bei der Suche
mittels einer
Vergleichsoperation (z.B. m_nr
> 10000), weil die Datenwerte,
die
logisch hintereinander kommen (10001, 10002 usw.), nicht
unbedingt in denselben oder
benachbarten physikalischen
Blöcken liegen.
Das
Hash-Verfahren kann besonders
empfohlen werden,
für
Tabellen, deren Schlüssel
aus mehreren Spalten
zusammengesetzt und dadurch sehr lang
sind.
12.1.3 ISAM
Die
Speicherstruktur ISAM ("Indexed Sequential Access
Method") unterscheidet sich von den
beiden vorherigen
dadurch, daß zusätzliche physikalische Seiten auf der Platte
für
den Index angelegt werden. Der
Index einer Tabelle,
die mit der ISAM-Speicherstruktur
erstellt wurde, kann eine
oder mehrere ihrer Spalten umfassen, die als
Primärschlüssel
bezeichnet werden.
Jede
Suche, die mit Hilfe des Index
ausgeführt werden kann,
ist
sehr effektiv. Dabei ist unerheblich,
ob die Suche nach
einem einzigen Datenwert (z.B. m_nr
= 10102) oder auf Grund
eines Vergleichoperators (z.B. m_nr
<= 20000) durchgeführt
wird, vorausgesetzt die Spalte m_nr ist der
Primärschlüssel.
Andererseits ist nicht
jede Suche ohne
Hilfe des Index
effektiv, weil sie sequentiell
durchgeführt werden muß.
Der
Index für ISAM wird immer bei
der Erstellung dieser
Speicherstruktur angelegt. Damit ist die Struktur des Index
festgelegt, und kann nur durch die
komplette Reorganisation
aller Daten geändert werden. Deswegen muß das Einfügen neuer
Reihen u.U. in sogenannten
Überlauf-Blöcken durchgeführt
werden, falls der existierende Datenblock, in den die Reihe
eingefügt werden soll, voll ist.
12.1.4 BTREE
Die
Speicherstruktur BTREE
("binary tree")
benutzt genauso
wie ISAM den
Index, um auf
die Daten einer
Tabelle
zuzugreifen. Der Unterschied zwischen BTREE und
ISAM liegt
nur darin, daß die von BTREE benutzte Indexdatei dynamisch
ist.
Das heißt, die Überlauf-Blöcke werden bei BTREE nicht
benutzt, weil nach jedem Einfügen einer Reihe die
Indexdatei
restrukturiert wird, falls
der existierende Datenblock, in
dem die Reihe mit Hilfe des Index
eingefügt werden soll, voll
ist.
Dieser Unterschied zwischen ISAM und BTREE zeigt gleichzeitig
den
jeweiligen Vorteil jeder der
beiden Speicherstrukturen:
ISAM kann bei der Suche in statischen Tabellen effektiver
eingesetzt werden, während BTREE bei Tabellen,
die viele
Änderungen aufweisen, verwendet
werden sollte.
12.2 Indexe
Wie
schon aus dem
vorherigen Abschnitt ersichtlich,
verwenden die Speicherstrukturen ISAM und BTREE
Indexe,
um
auf Daten zuzugreifen. Ein Index kann
mit dem
Inhaltsverzeichnis eines Buches verglichen werden. Mit Hilfe
eines Inhaltsverzeichnisses ist
es möglich, einen Begriff,
der im Buch ein- oder
mehrmals vorkommt, gezielt zu suchen
und anschließend im Text
ausfindig zu machen. Um Indexe
zu
erklären, werden wir die
BTREE-Speicherstruktur bei
INGRES
näher erklären.
Indexe der
BTREE-Speicherstruktur sind mit
Hilfe einer
Datenstruktur namens B+ -Baum intern aufgebaut. Ein B+
-Baum
hat eine baumartige Datenstruktur
mit der Eigenschaft, daß
alle
Blattknoten des Baums
gleich weit von
der Wurzel
entfernt sind. Diese Struktur
wird auch aufrechterhalten,
wenn neue Einträge eingefügt, bzw.
alte gelöscht werden.
Am
Beispiel der Tabelle mitarbeiter
wird die Struktur eines
B+ -Baums dargestellt und die
direkte Suche nach der Reihe
mit
der Personalnummer 25348 in
der Tabelle mitarbeiter
erläutert. (Das setzt voraus, daß die
Spalte m_nr der Tabelle
mitarbeiter indiziert ist.)
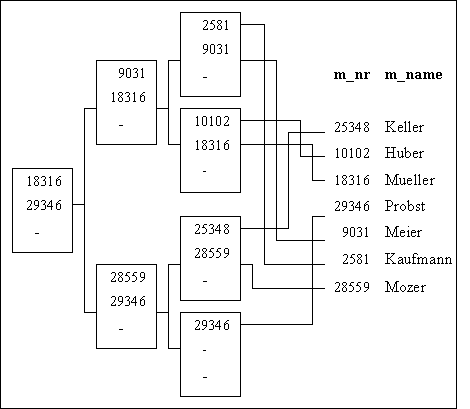
Abb. 12-1 B+-Baum für
die Tabelle mitarbeiter
Wie
aus Abbildung 12-1
ersichtlich, beinhaltet jeder
B+ -Baum eine Wurzel,
eine Blattknotenebene und
keine,
eine oder mehrere dazwischen liegenden
Knotenebenen. Die
Blattknotenebene enthält einen Eintrag für jeden
Datenwert
der Spalte(n), für die ein Index
erstellt wurde, und je einen
Zeiger, der die
physikalische Adresse der
entsprechenden
Reihe enthält.
Das Suchen des Datenwertes
25348 verläuft folgendermaßen:
Angefangen von der Wurzel des B+
-Baums wird immer der Wert
gesucht, der größer oder gleich
dem Suchwert ist. Abbildung
12-1 folgend wird zuerst der
Datenwert 29348 auf der höchsten
Ebene ausgesucht, danach der Wert 28559 auf der nächsten und
der gesuchte Wert 25348 auf der niedrigsten Ebene. Mit
Hilfe
des dazugehörigen Zeigers wird anschließend
die entsprechende
Reihe ausgewählt. (Eine
andere, aber äquivalente
Suchart
wäre, stets den Wert zu suchen, der
kleiner oder gleich dem
Suchwert ist.)
Besonders bei Tabellen mit sehr
vielen Reihen ist der Vorteil
der
direkten Suche offensichtlich.
Das System findet jede
Reihe einer Tabelle mit wenigen
Ein/Ausgabe-Operationen immer
in etwa gleich kurzer Zeit,
während die sequentielle Suche
um
soviel länger dauert, je weiter eine Reihe vom Anfang der
Tabelle entfernt ist.
12.2.1 SQL-Anweisungen in Bezug auf Indexe
INGRES ermöglicht das Erstellen und
Löschen von Indexen. Beim
Erstellen eines Index trägt
INGRES die Information über die
Indexeigenschaften in der Systemtabelle iiindexes ein.
Diese
Systemtabelle beinhaltet je eine
Reihe für jeden erstellten
Index. Die Systemtabelle iiindexes enthält
u.a. folgende
Spalten:
-
den Namen des erstellten Index;
-
den Namen des Eigentümers, der den Index erstellt hat;
-
den Namen der Tabelle, zu welcher der Index gehört;
-
den Indextyp.
Die
ausführliche Beschreibung dieser
Systemtabelle befindet
sich in Kapitel 11.
Mit der Anweisung CREATE INDEX wird
ein Index erstellt. Diese
Anweisung hat folgende Form:
CREATE [UNIQUE] INDEX index_name
ON tabelle (sp_1 [ASC|DESC] [,sp_2 [ASC|DESC] ...])
[WITH-Klausel];
index_name kennzeichnet den Namen des erstellten Index. Für
den
Indexnamen index_name
gilt dasselbe wie für den Namen
einer Tabelle: Er muß
mit einem Buchstaben
beginnen und
darf
maximal 24 Zeichen lang sein. Ein Index kann für eine
oder mehrere Spalten erstellt werden. Ein Index, der
mehrere
Spalten umfaßt, wird zusammengesetzter
Index genannt. Ein
zusammengesestzter Index darf maximal 30 Spalten umfassen.
Jede
Spalte einer Tabelle kann indiziert sein, wobei der Typ
und die Länge der Spalte beliebig
sein können.
Die Angabe ASC bzw. DESC definiert
die Sortierfolge der
Reihen der Tabelle. Falls
ASC angegeben ist, werden die
Reihen der indizierten Spalte
aufsteigend und bei
DESC
absteigend sortiert. Für einen zusammengesetzten Index gilt,
daß
zuerst auf Grund der
erstangegebenen Spalte in
der
CREATE INDEX-Anweisung sortiert wird. Wenn zwei oder mehrere
Datenwerte in dieser Spalte gleich sind, wird auf Grund der
zweiten Spalte sortiert, usw. Falls weder ASC
noch DESC
angegeben ist, wird ASC als
Voreinstellung angenommen.
Die
optionale Angabe UNIQUE
legt fest, daß jeder Datenwert
nur
einmal in der
indizierten Spalte vorkommen
darf.
Bei
einem zusammengesetzten Index
darf der verkettete
Wert
aller Datenwerte der
zusammenhängenden Spalten nur
einmal vorkommen. Falls UNIQUE nicht angegeben ist,
dürfen
Datenwerte in der indizierten Spalte
mehrfach vorkommen.
Die
WITH-Klausel enthält das Schlüsselwort WITH, gefolgt von
einer oder mehreren der folgenden Angaben, die durch Kommata
voneinander getrennt sind:
STRUCTURE=CBTREE|BTREE|CISAM|ISAM|CHASH|HASH
KEY = (spalten_liste),
FILLFACTOR = n,
MINPAGES = n,
MAXPAGES = n,
LEAFFILL = n,
NONLEAFFILL = n und
LOCATION = (bereich_1,...)
|
Angabe |
Funktion |
|
STRUCTURE |
Mit STRUCTURE kann die Speicherstruktur
eines Index festgelegt werden. ISAM, BTREE und HASH sind die Angaben für die
entsprechenden Speicherstrukturen, die im vorherigen Abschnitt erläutert
wurden. CBTREE und CHASH bezeichnen komprimierte BTREE- bzw.
HASH-Speicherstrukturen, d.h. die Datenwerte der indizierten Spalte werden in
der Indexdatei komprimiert gespeichert. Falls bei der Erstellung eines Index
keine STRUCTURE-Angabe vorliegt, wird standardmäßig ISAM genommen. |
|
KEY |
Die Angabe KEY=(spalten_liste) definiert
die geordnete Untermenge aller Spalten eines Index. Falls z.B. ein Index für die Spalten a, b,
c und d definiert ist, kann die KEY-Angabe a, ab,
abc oder abcd sein. (Die Voreinstellung ist abcd.) |
|
MINPAGES MAXPAGES |
bzw. MINPAGES bzw. MAXPAGES kennzeichnen
die aproximativ minimale bzw. die aproximativ maximale Anzahl der
physikalischen Seiten, die eine Tabelle mit der HASH- oder CHASH-Struktur
haben muß. Falls sowohl MINPAGES als auch MAXPAGES in einer CREATE
INDEX-Anweisung spezifiziert sind, darf MINPAGES nicht größer als MAXPAGES
sein. |
|
LEAFFILL |
Die LEAFFILL-Angabe definiert den
Prozentsatz des belegten Speichers aller Speicherseiten, die für die
Blattknoten eines Index reserviert sind. Die Angabe LEAFFILL ist nur für die
Tabellen mit der BTREE- bzw. CBTREE-Struktur zulässig. |
|
NONLEAFFILL |
Die NONLEAFFILL-Angabe definiert den
Prozentsatz des freigehaltenen Speichers aller Speicherseiten, die für das
Innere des Index reserviert sind. Die
Angabe NONLEAFFILL ist nur für die Tabellen mit der BTREE- bzw.
CBTREE-Struktur zulässig. |
|
Die LOCATION-Angabe definiert
Speicherbereiche, wo ein Index nach seiner Erstellung gespeichert werden
soll. Die angegebenen
Speicherbereiche müssen dem INGRES-System im voraus bekannt sein.
Falls LOCATION nicht angegeben ist, wird der Index standardmäßig im Datenbank-Speicherbereich gespeichert. |
Beispiel 12.1
Erstellen Sie einen Index
für die Spalte m_nr der Tabelle
mitarbeiter.
CREATE INDEX i_mit_mnr
ON mitarbeiter (m_nr);
Beispiel 12.2
Erstellen Sie einen zusammengesetzten Index für die Spalten
m_nr und pr_nr der
Tabelle arbeiten. Die
Werte in den
zusammenhängenden Spalten
m_nr und pr_nr dürfen nicht
mehrfach vorkommen. Die
Speicherstruktur dieses Index
soll
BTREE
sein.
CREATE UNIQUE INDEX
i_arb_mpr
ON arbeiten (m_nr,
pr_nr)
WITH STRUCTURE = BTREE;
Das Erstellen eines UNIQUE-Index für eine
Spalte ist nicht
möglich, falls diese Spalte
mehrfach vorhandene Werte
enthält. Damit ein solcher
Index erstellt werden
kann,
darf
jeder existierende Datenwert
in der Spalte nur einmal
vorkommen, was auch für
NULL-Werte gilt.
Wie
das INGRES-System die
Erstellung eines UNIQUE-Index
für
eine Spalte mit
mehrfach vorhandenen Werten
nicht
zuläßt, so ist es nicht
möglich, mehrfach vorhandene Werte
in
einer Spalte, für die ein UNIQUE-Index schon erstellt
wurde, einzufügen. Der Versuch,
mit einer UPDATE-
bzw.
INSERT-Anweisung einen
schon existierenden Datenwert
in
einer Spalte mit UNIQUE-Index einzufügen, wird vom System
abgewiesen.
Im
folgenden Beispiel wird die Möglichkeit gezeigt,
wie
mehrfach vorhandene Werte einer Spalte gefunden und entfernt
werden können, damit ein
UNIQUE-Index für diese
Spalte
erstellt werden kann.
Beispiel 12.3
Entfernen Sie alle Reihen
der Tabelle arbeiten, bis
auf
die Reihen, die
für jeden Mitarbeiter
das jüngste
Einstellungsdatum enthalten.
CREATE VIEW v_hilftab (m_nr, max_dat)
AS SELECT m_nr, max(einst_dat)
FROM arbeiten
GROUP BY m_nr
HAVING COUNT(*) > 1;
DELETE FROM arbeiten
WHERE EXISTS
(SELECT *
FROM
v_hilftab
WHERE arbeiten.m_nr = v_hilftab.m_nr)
AND arbeiten.einst_dat <
(SELECT max_dat
FROM v_hilftab
WHERE
arbeiten.m_nr = v_hilftab.m_nr);
Das View v_hilftab, das in
Beispiel 12.3 zuerst erstellt
wurde, enthält die Reihen der Tabelle arbeiten, deren Spalte
m_nr mehrfach vorhandene Werte beinhaltet und von
diesen
nur diejenigen mit dem
jüngsten Einstellungsdatum. Folgende
SELECT-Anweisung zeigt alle Reihen
des Views v_hilftab:
SELECT *
FROM v_hilftab;
Das
Ergebnis ist:
|
m_nr |
max_dat |
|
9031 |
15-apr-1989 |
|
29346 |
01-apr-1989 |
|
10102 |
01-jan-1989 |
|
28559 |
01-feb-1989 |
(4 rows)
Die
erste innere SELECT-Anweisung
in der WHERE-Klausel der
DELETE-Anweisung wählt alle
mehrfach vorhandenen Reihen der
Tabelle arbeiten aus. Bei
der zweiten SELECT-Anweisung wird
die Auswahl auf
nur die Reihen eingeschränkt, deren Spalte
einst_dat das jüngste Einstellungsdatum nicht enthält.
Damit
werden mit Hilfe des Views v_hilftab alle Reihen gelöscht,
deren Spalte m_nr mehrfach vorhandene Werte und deren Spalte
einst_dat die
Datenwerte, die nicht
die jüngsten sind,
enthält.
Die
Tabelle arbeiten hat,
nachdem die Anweisungsfolge in
Beispiel 12.3 abgearbeitet wird,
folgenden Inhalt:
|
m_nr |
pr_nr |
aufgabe |
einst_dat |
|
9031 |
p1
|
Gruppenleiter |
15-apr-1989 |
|
29346 |
p1
|
Sachbearbeiter |
01-apr-1989 |
|
2581 |
p3
|
Projektleiter |
15-oct-1989 |
|
18316 |
p2 |
|
01-jun-1989 |
|
25348 |
p2
|
Sachbearbeiter |
15-feb-1988 |
|
10102 |
p3
|
Gruppenleiter |
01-jan-1989 |
|
28559 |
p2 |
Sachbearbeiter |
01-feb-1989 |
Wie aus der obigen Darstellung
ersichtlich, kommt jeder
Datenwert in der Spalte
m_nr nur einmal vor. Damit ist es
jetzt möglich, einen UNIQUE-Index für
die Tabelle arbeiten zu
erstellen.
Das
erstellte View v_hilftab
kann, nachdem die Aufgabe in
Beispiel 12.3 gelöst wurde, mit der
Anweisung
DROP VIEW v_hilftab;
gelöscht
werden, weil wir es nur
als Hilfsmittel benutzt
haben.
Mit
der Anweisung DROP
INDEX wird der
erstellte Index
gelöscht. Die allgemeine Form
dieser Anweisung sieht
folgendermaßen aus:
DROP INDEX index_name1 [,index_name2,...];
Beispiel 12.4
Löschen Sie den Index, der in
Beispiel 12.1 erstellt wurde.
DROP INDEX i_mit_mnr
12.2.2 Indexe und Schlüssel
Wie
wir schon gezeigt haben,
sind Indexe ein
Teil der
SQL-Sprache. Im
Unterschied zu ihnen
sind Schlüssel im
ANSI-SQL-Standard vom 1986
nicht definiert, jedoch aber im
SQL2-Standard.
Bevor der Zusammenhang zwischen
Indexen und Schlüsseln
erklärt wird, müssen die
verschiedenen Schlüssel erläutert
werden. Im relationalen Datenmodell
existieren folgende
Schlüsselarten:
a) Kandidatenschlüssel;
b) Primärschlüssel und
c) Fremdschlüssel.
Der
Kandidatenschlüssel
kennzeichnet eine Spalte
oder
Spaltengruppe einer Tabelle,
für die die
minimale
Eindeutigkeit gilt. Eine
Tabelle kann einen oder
mehrere
Kandidatenschlüssel aufweisen. Einer dieser Schlüssel wird
ausgewählt und als Primärschlüssel bezeichnet.
Als
Fremdschlüssel wird eine Spalte oder Spaltengruppe einer
Tabelle bezeichnet, die
Primärschlüssel einer anderen Tabelle
ist.
Die Datenwerte der
Spalte, die einen Fremdschlüssel
darstellt, bilden gewöhnlich eine Untermenge der Datenwerte
der Spalte, die den entsprechenden
Primärschlüssel bildet.
Die Beispieldatenbank enthält
folgende Schlüssel:
a) Die Spalte abt_nr der Tabelle abteilung
ist sowohl ein
Kandidaten- als auch ein
Primärschlüssel.
b) Die Spalte pr_nr
der Tabelle projekt ist sowohl ein
Kandidaten- als auch ein
Primärschlüssel.
c) Die Spalte m_nr der Tabelle mitarbeiter
ist sowohl ein
Kandidaten- als auch ein
Primärschlüssel. Gleichzeitig ist
die Spalte abt_nr ein
Fremdschlüssel.
d) Die Spaltengruppe (m_nr, pr_nr)
der Tabelle arbeiten
ist sowohl ein Kandidaten-
als auch ein Primärschlüssel.
Zusätzlich dazu ist
jede dieser Spalten
ein
Fremdschlüssel.
Für
jeden Primär- und
Kandidatenschlüssel einer Tabelle
soll grundsätzlich ein Index
erstellt werden, der
die
UNIQUE-Angabe enthält. Die Angabe
UNIQUE steht im
Zusammenhang mit der
Definition beider Schlüssel;
sowohl
Primär- als auch
Kandidatenschlüssel lassen keine
mehrfach
vorhandenen Datenwerte zu. Zusätzlich soll jede Spalte, die
einen Primär- bzw. Kandidatenschlüssel darstellt, die NOT
NULL-Angabe in der CREATE TABLE-Anweisung enthalten. Die
Notwendigkeit der NOT NULL-Angabe
stammt aus dem relationalen
Modell. Jeder Primär-- bzw.
Kandidatenschlüssel wird im
relationalen Modell
als eine (mathematische) Funktion
betrachtet, die jedes Element
eindeutig identifiziert.
Beispiel 12.5
Erstellen Sie einen UNIQUE-Index für jeden Primär-
und
Kandidatenschlüssel der
Beispieldatenbank.
CREATE UNIQUE INDEX i_abt_nr ON abteilung (abt_nr);
CREATE UNIQUE INDEX i_m_nr ON
mitarbeiter (m_nr);
CREATE UNIQUE INDEX i_pr_nr ON projekt (pr_nr);
CREATE UNIQUE INDEX i_mpr_nr ON arbeiten (m_nr,pr_nr);
Auch
für jeden Fremdschlüssel ist es
empfehlenswert, einen
Index zu erstellen. Eine
der Joinspalten, die
bei der
Verknüpfung zweier Tabellen benutzt wird,
stellt gewöhnlich
einen Fremdschlüssel dar.
Das Erstellen eines
Index für
einen Fremdschlüssel wird die
Abarbeitungszeit eines Joins
wesentlich verkürzen. Die Angabe
UNIQUE wäre in diesem Fall
falsch, weil ein Fremdschlüssel mehrfach vorhandene Werte
zuläßt.
Beispiel 12.6
Erstellen Sie einen Index
für jeden Fremdschlüssel der
Beispieldatenbank.
CREATE INDEX i_m_abtnr ON mitarbeiter (abt_nr);
CREATE INDEX i_arb_mnr ON arbeiten (m_nr);
CREATE INDEX i_arb_prnr ON arbeiten (pr_nr);
12.2.3 Kriterien zur Erstellung eines Index
Obwohl INGRES keine
Einschränkungen bezüglich der
Anzahl
von
Indexen aufweist, ist
es sinnvoll, diese
Anzahl
relativ gering zu halten.
Erstens verbraucht jeder
Index
Speicherplatz; wenn für eine
Anwendung sehr viele
Indexe
erstellt wurden, kann es sogar
vorkommen, daß die Indexe mehr
Speicherplatz brauchen als alle
Datenwerte einer Datenbank.
Zweitens werden im Unterschied
zu Abfragen, die mit Hilfe
eines Index wesentlich
beschleunigt werden können,
die
Anweisungen INSERT und DELETE u.U.
mit der Speicherstruktur
BTREE bzw. CBTREE langsamer.
Der Grund dafür ist, daß jedes
Einfügen bzw. Löschen der
Reihen einer Tabelle mit
einer
indizierten Spalte u.U. eine
Änderung der Struktur
der
Indexdatei verursacht. Dementsprechend wird die
Indexdatei
auch geändert, wenn eine
indizierte Spalte selbst
geändert
wird.
Im folgenden werden
wir einige Empfehlungen geben, wann ein
Index erstellt werden soll und wann
nicht. Für alle Beispiele
dieses Kapitels gilt die
Annahme, daß alle Tabellen der
Beispieldatenbank eine große Anzahl von
Reihen haben.
a) WHERE-Klausel
Wenn
die WHERE-Klausel in
einer SELECT-Anweisung eine
Bedingung mit einer einzigen
Spalte enthält, ist
es
empfehlenswert, diese Spalte zu indizieren. Dabei ist es
wichtig zu wissen, welchen
Prozentsatz der Reihen
die
SELECT-Anweisung auswählt. Das Erstellen eines
Index wird
die Abfrage am stärksten beschleunigen, wenn der Prozentsatz
unter 5% liegt. Andererseits ist
es nicht sinnvoll, wenn
die
Menge der ausgewählten
Reihen konstant 80% oder
mehr
beträgt, einen Index zu
erstellen. In diesem Fall
werden
für
die existierende Indexdatei
zusätzliche E/A-Operationen
notwendig, die dann die
Zeitgewinne, die mit der direkten
Suche erreicht wurden, zunichte
machen.
Die WHERE-Klausel
kommt auch in
den
Datenmanipulationsanweisungen UPDATE und DELETE vor. Für die
WHERE-Klausel gilt bei
diesen beiden Anweisungen ähnliches,
was
schon für die SELECT-Anweisung gesagt wurde. Der einzige
Unterschied ist, daß die
UPDATE- und
DELETE-Anweisung bei
der
Speicherstruktur BTREE bzw.
CBTREE u.U. zusätzliche
Änderungen der Indexdatei
verursachen. Dieser Zeitverlust
muß
in Betracht gezogen
werden, wenn die
Entscheidung
getroffen wird, ob der Index
erstellt werden soll
oder
nicht. (In der Praxis wird die
Spalte, die in der Bedingung
einer WHERE-Klausel in einer
UPDATE- bzw. DELETE-Anweisung
vorkommt, meist auch in einer
SELECT-Anweisung benutzt.)
b) AND-Operator
Wenn eine Bedingung in
der WHERE-Klausel einen
oder
mehrere AND-Operatoren enthält,
empfiehlt es sich,
einen
zusammengesetzten Index
zu erstellen, der
alle Spalten
umfaßt, die in der Bedingung vorkommen. Dabei spielt die
Länge aller Spalten, für die
der zusammengesetzte Index
erstellt werden soll, eine
wesentliche Rolle. Je größer die
Gesamtlänge aller Spalten ist, desto
weniger empfehlenswert
ist es, den Index zu erstellen.
Beispiel 12.7
CREATE INDEX i_arb_mdat
ON arbeiten (m_nr, einst_dat);
SELECT *
FROM arbeiten
WHERE m_nr = 29346
AND einst_dat = '01-apr-1989';
In Beispiel 12.7 wird mit der SELECT-Anweisung sowohl nach
der
Personalnummer als auch
nach dem Einstellungsdatum des
Mitarbeiters gesucht. In diesem Fall
empfiehlt es sich, einen
zusammengesetzten Index zu erstellen,
wie es auch im Beispiel
gemacht wurde.
c) Join
Beim Verknüpfen zweier Tabellen
mit Join ist
es
empfehlenswert, beide Joinspalten zu indizieren. Joinspalten
stellen gewöhnlich den Primärschlüssel der
einen und den
entsprechenden Fremdschlüssel der anderen
Tabelle dar. Nach
den Kriterien des vorherigen
Abschnitts sollten diese Spalten
indiziert sein.
Beispiel 12.8
SELECT m_name, m_vorname
FROM mitarbeiter, arbeiten
WHERE mitarbeiter.m_nr = arbeiten.m_nr
AND einst_dat = '15-oct-1989';
In diesem
Beispiel wäre es
sinnvoll, für die
Spalten
mitarbeiter.m_nr und arbeiten.m_nr je
einen Index zu
erstellen. Nach dem Kriterium b) soll ein zusätzlicher Index
für die Spalte einst_dat
erstellt werden.
12.3 Allgemeine Kriterien zur Verbesserung der Effizienz
Im
letzten Abschnitt haben
wir gezeigt, wie
das
Leistungsverhalten einer Datenbankanwendung mit
Hilfe von
Indexen verbessert werden kann.
In diesem Abschnitt wird
erläutert, wie die Programmierung die
Effizienz der Anwendung
beeinflussen kann.
Das INGRES-System erarbeitet für eine gegebene SQL-Anweisung
gleichzeitig mehrere mögliche Lösungen. Nachdem die
Lösungen
erstellt wurden, versucht ein spezieller Systemteil
- der
Optimierer - die effizienteste Lösung auszuwählen. Der
INGRES-Optimierer ist nicht
imstande, für jeden Fall
die
bestmögliche Lösung zu
finden. Deswegen ist es sehr wichtig
herauszufinden, wie der Programmierer die Effizienz seiner
Anwendung verbessern kann. Für
INGRES gelten folgende
Kriterien:
12.3.1 Join statt korrelierter Unterabfrage
Die
meisten SELECT-Anweisungen mit
der korrelierten
Unterabfrage können auch
mit Hilfe von
Join dargestellt
werden. Diese beiden äquivalenten Lösungsmethoden
unterscheiden sich dadurch, daß Join wesentlich effizienter
als die korrelierte Unterabfrage ist. Dies wird in folgendem
Beispiel verdeutlicht.
Beispiel 12.9
Nennen Sie die Namen aller Mitarbeiter, die in Projekt p3
arbeiten.
A. SELECT m_name
FROM mitarbeiter, arbeiten
WHERE mitarbeiter.m_nr = arbeiten.m_nr
AND pr_nr = 'p3';
B. SELECT m_name
FROM mitarbeiter
WHERE 'p3' IN
(SELECT pr_nr
FROM
arbeiten
WHERE mitarbeiter.m_nr = arbeiten.m_nr);
Die Lösung A ist effizienter als die
Lösung B. Bei der Lösung
B muß jede Reihe der äußeren
SELECT-Anweisung mit allen
Reihen der inneren SELECT-Anweisung
verglichen werden. Dieses
Verfahren ist nicht optimal, weil das einmalige Suchen nach
dem
Datenwert p3 in der Spalte pr_nr (wie bei
Lösung A)
wesentlich schneller ist.
12.3.2 Unvollständige Anweisungen
In der Praxis kann es
vorkommen, daß der
Programmierer
aus
Versehen eine INGRES-SQL-Anweisung unvollständig angibt.
Diese Anweisung ist nicht
nur fehlerhaft, sondern kann
auch das Leistungsverhalten der
ganzen Anwendung sehr
beeinträchtigen. Typisches Beispiel
dafür ist das Kartesische
Produkt.
Das
Kartesische Produkt ist
schon in Kapitel 7 ausführlich
beschrieben worden. Das Ergebnis eines Kartesischen Produkts
enthält jede Kombination der
Reihen beider Tabellen. Wenn
eine
Tabelle z.B. 10000 und die
andere 100 Reihen
hat,
enthält das Kartesische Produkt dieser Tabellen als Ergebnis
insgesamt eine Million Reihen.
Dementsprechend groß ist der
Zeitverlust, der bei dieser
Verknüpfung entsteht.
Das absichtliche Erzeugen eines Kartesischen Produkts ist in
der Praxis sehr selten. Vielmehr
handelt es sich um einen
Fehler des
Programmierers, der vergessen hat, das notwendige
Join in der WHERE-Klausel anzugeben.
12.3.3 LIKE-Operator
Der LIKE-Operator ist ein Vergleichsoperator, der Datenwerte
einer Spalte mit einer vorgegebenen Zeichenkette vergleicht.
Falls diese Spalte indiziert ist,
wird die Suche nach der
Zeichenkette mit Hilfe des
existierenden Index ausgeführt.
Die Verwendung
des Zeichens "%" bzw.
"_" am Anfang
der
Zeichenkette macht es
aber unmöglich, das Suchen von
der
Wurzel des Indexbaums aus zu starten.
Beispiel 12.10
Finden Sie die Personalnummer
aller Mitarbeiter, deren Name
mit "mann" endet.
SELECT m_nr
FROM mitarbeiter
WHERE m_name LIKE '%mann';
In
Beispiel 12.10 kann die Suche
nicht von der Wurzel des
Indexbaums aus durchgeführt werden,
auch wenn der Index für
die Spalte m_name existiert. Der
Grund dafür ist, daß die
ersten Zeichen des Vergleichsmusters in der Bedingung nicht
bekannt sind.
12.4 Optimieren von Suchanweisungen
Die Aufgabe des Optimierers ist es,
die besten Strategien für
die Ausführung der
Datenmanipulationsanweisungen
(meistens
Abfragen) zu erstellen. INGRES
erlaubt dem Benutzer, den
ausgewählten Ausführungsplan ("query execution plan" - QEP)
mit Hilfe des Terminalmonitors zu
verfolgen.
Eine
andere Möglichkeit, die Ausführung
der Abfragen zu
optimieren, bietet
die MODIFY-Anweisung an. Diese
Anweisung
modifiziert die Speicherstruktur einer Tabelle
oder eines
Index. Die Syntax dieser Anweisung
ist:
MODIFY tab_name|index_name TO neu_struktur
[ON spalten_name [ASC|DESC]],...
[WITH-Klausel];
Die Speicherstruktur der Tabelle
tab_name bzw. des
Index
index_name wird mit
der MODIFY-Anweisung in neu_struktur
geändert. Die WITH-Klausel hat
dieselben Angaben wie
die
gleichnamige Klausel bei
der CREATE INDEX-Anweisung.
Damit
ist es möglich, mit Hilfe der
MODIFY-Anweisung auch den
Speicherort einer Tabelle zu ändern.
Beispiel
12.11
MODIFY mitarbeiter TO
CBTREE ON m_nr
WITH LEAFFILL = 60,
FILLFACTOR = 50;
Die
Speicherstruktur der Tabelle mitarbeiter wird in Beispiel
12.11 in CBTREE umgewandelt.
Die physikalischen Seiten, die
für
Daten reserviert sind,
können bis zu 50% und die für
Blattknoten bis zu 60% aufgefüllt
werden.
Die SET-Anweisung mit der
RESULT_STRUCTURE-Angabe kann auch
benutzt werden, um die
Speicherstruktur einer Tabelle
zu
ändern, falls diese Tabelle
aus einer schon existierenden
abgeleitet wird.
Beispiel 12.12
SET RESULT_STRUCTURE HASH;
CREATE tab_neu
AS SELECT *
FROM
mitarbeiter;
CREATE INDEX i_tab_neu
ON tab_neu(m_nr)
WITH
STRUCTURE=HASH, MINPAGES=30;
In
Beispiel 12.12 wird die Tabelle tab_neu erstellt und mit
den Reihen der Tabelle mitarbeiter
geladen. Die logischen
Strukturen der beiden Tabellen sind identisch, während
die
Speicherstruktur der Tabelle
tab_neu in HASH
modifiziert
wird.
Weil die Hash-Speicherstruktur
statisch ist, ist es sinnvoll,
einen Schlüssel mit der
minimalen Anzahl der physikalischen
Seiten zu definieren.
Aufgaben
A.12.1 Erstellen
Sie unter der
Annahme, daß alle
Tabellen
der Beispieldatenbank
eine sehr große
Anzahl von
Reihen haben, die notwendigen Indexe für folgende
SELECT-Anweisungen:
a) SELECT m_nr, m_name, m_vorname
FROM mitarbeiter
WHERE m_name = 'Kaufmann';
b) SELECT m_nr, m_name, m_vorname
FROM mitarbeiter
WHERE m_name =
'Meier'
AND m_vorname =
'Rainer';
c)
SELECT aufgabe
FROM arbeiten, mitarbeiter
WHERE arbeiten.m_nr = mitarbeiter.m_nr;
d) SELECT m_name,
m_vorname
FROM mitarbeiter, abteilung
WHERE mitarbeiter.abt_nr=abteilung.abt_nr
AND abt_name = 'Beratung';